Quick Start User Guide
Overview
Slurm is an open source,
fault-tolerant, and highly scalable cluster management and job scheduling system
for large and small Linux clusters. Slurm requires no kernel modifications for
its operation and is relatively self-contained. As a cluster workload manager,
Slurm has three key functions. First, it allocates exclusive and/or non-exclusive
access to resources (compute nodes) to users for some duration of time so they
can perform work. Second, it provides a framework for starting, executing, and
monitoring work (normally a parallel job) on the set of allocated nodes. Finally,
it arbitrates contention for resources by managing a queue of pending work.
Slurmは、オープンソースで、フォールトトレラントで、拡張性の高いクラスター管理と大規模および小規模のLinuxクラスター向けのジョブスケジューリングシステムです。Slurmは操作にカーネルの変更を必要とせず、比較的自己完結型です。クラスターワークロードマネージャーとして、Slurmには3つの主要な機能があります。最初に、リソース(計算ノード)への排他的および/または非排他的アクセスを一定期間ユーザーに割り当てて、ユーザーが作業を実行できるようにします。次に、割り当てられたノードのセットで作業(通常は並列ジョブ)を開始、実行、および監視するためのフレームワークを提供します。最後に、保留中の作業のキューを管理することにより、リソースの競合を調停します。
Architecture
As depicted in Figure 1, Slurm consists of a slurmd daemon running on
each compute node and a central slurmctld daemon running on a management node
(with optional fail-over twin).
The slurmd daemons provide fault-tolerant hierarchical communications.
The user commands include: sacct, salloc, sattach,
sbatch, sbcast, scancel, scontrol,
sinfo, sprio, squeue, srun,
sshare, sstat, strigger and sview.
All of the commands can run anywhere in the cluster.
図1に示すように、Slurmは、各計算ノードで実行されるslurmdデーモンと、管理ノード(オプションのフェイルオーバーツイン付き)で実行される中央のslurmctldデーモンで構成されています。slurmdデーモンは、フォールトトレラントな階層型通信を提供します。ユーザーコマンドには、sacct、salloc、sattach、sbatch、sbcast、scancel、scontrol、sinfo、sprio、squeue、srun、sshare、sstat、strigger、sviewがあります。すべてのコマンドは、クラスター内の任意の場所で実行できます。
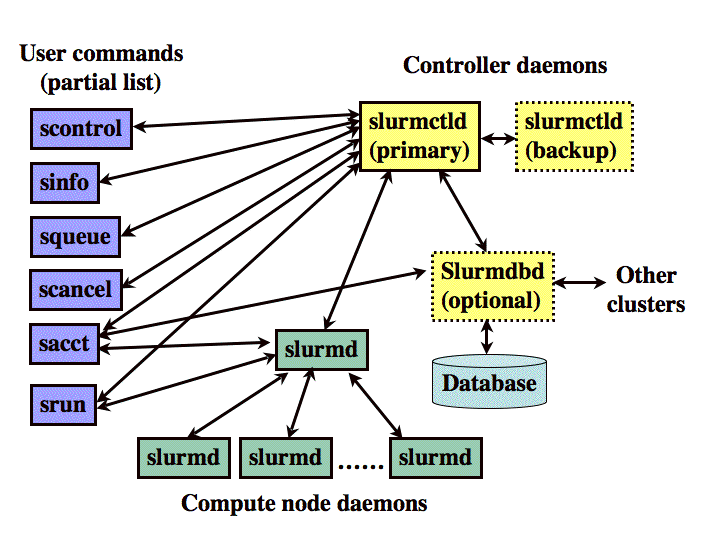 Figure 1. Slurm components
Figure 1. Slurm components
The entities managed by these Slurm daemons, shown in Figure 2, include
nodes, the compute resource in Slurm,
partitions, which group nodes into logical (possibly overlapping) sets,
jobs, or allocations of resources assigned to a user for
a specified amount of time, and
job steps, which are sets of (possibly parallel) tasks within a job.
The partitions can be considered job queues, each of which has an assortment of
constraints such as job size limit, job time limit, users permitted to use it, etc.
Priority-ordered jobs are allocated nodes within a partition until the resources
(nodes, processors, memory, etc.) within that partition are exhausted. Once
a job is assigned a set of nodes, the user is able to initiate parallel work in
the form of job steps in any configuration within the allocation. For instance,
a single job step may be started that utilizes all nodes allocated to the job,
or several job steps may independently use a portion of the allocation.
これらのSlurmデーモンが管理するエンティティには、図2に示すように、ノード、Slurmの計算リソース、パーティション、ノードを論理的な(重複している可能性がある)セット、ジョブ、または指定された量のユーザーに割り当てられたリソースの割り当てにグループ化します時間、およびジョブステップは、ジョブ内の(場合によっては並列の)タスクのセットです。パーティションはジョブキューと見なすことができ、それぞれにジョブサイズの制限、ジョブの時間制限、使用を許可されたユーザーなどのさまざまな制約があります。優先順位付けされたジョブは、リソース(ノード、そのパーティション内のプロセッサ、メモリなど)が使い果たされています。ジョブにノードのセットが割り当てられると、ユーザーは割り当て内の任意の構成でジョブステップの形式で並列作業を開始できます。例えば、
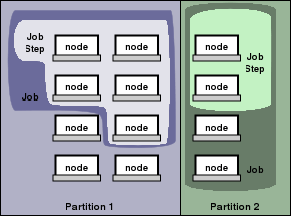 Figure 2. Slurm entities
Figure 2. Slurm entities
Commands
Man pages exist for all Slurm daemons, commands, and API functions. The command
option --help also provides a brief summary of
options. Note that the command options are all case sensitive.
すべてのSlurmデーモン、コマンド、およびAPI関数のマニュアルページが存在します。コマンドオプション--helpもオプションの簡単な要約を提供します。コマンドオプションはすべて大文字と小文字が区別されることに注意してください。
sacct is used to report job or job
step accounting information about active or completed jobs.
sacctは、アクティブなジョブまたは完了したジョブに関するジョブまたはジョブステップアカウンティング情報を報告するために使用されます。
salloc is used to allocate resources
for a job in real time. Typically this is used to allocate resources and spawn a shell.
The shell is then used to execute srun commands to launch parallel tasks.
sallocは、ジョブにリソースをリアルタイムで割り当てるために使用されます。通常、これはリソースの割り当てとシェルの生成に使用されます。次にシェルを使用してsrunコマンドを実行し、並列タスクを起動します。
sattach is used to attach standard
input, output, and error plus signal capabilities to a currently running
job or job step. One can attach to and detach from jobs multiple times.
sattachは、標準入力、出力、およびエラーとシグナル機能を現在実行中のジョブまたはジョブステップにアタッチするために使用されます。ジョブに複数回アタッチしたり、ジョブからデタッチしたりできます。
sbatch is used to submit a job script
for later execution. The script will typically contain one or more srun commands
to launch parallel tasks.
sbatchは、後で実行するためにジョブスクリプトを送信するために使用されます。スクリプトには通常、並列タスクを起動するための1つ以上のsrunコマンドが含まれます。
sbcast is used to transfer a file
from local disk to local disk on the nodes allocated to a job. This can be
used to effectively use diskless compute nodes or provide improved performance
relative to a shared file system.
sbcastは、ジョブに割り当てられたノード上のローカルディスクからローカルディスクにファイルを転送するために使用されます。これを使用して、ディスクレスコンピューティングノードを効果的に使用したり、共有ファイルシステムに比べてパフォーマンスを向上させることができます。
scancel is used to cancel a pending
or running job or job step. It can also be used to send an arbitrary signal to
all processes associated with a running job or job step.
scancelは、保留中または実行中のジョブまたはジョブステップをキャンセルするために使用されます。また、実行中のジョブまたはジョブステップに関連付けられているすべてのプロセスに任意の信号を送信するためにも使用できます。
scontrol is the administrative tool
used to view and/or modify Slurm state. Note that many scontrol
commands can only be executed as user root.
scontrolは、Slurmの状態を表示または変更するために使用される管理ツールです。多くのscontrolコマンドは、ユーザーrootとしてのみ実行できることに注意してください。
sinfo reports the state of partitions
and nodes managed by Slurm. It has a wide variety of filtering, sorting, and formatting
options.
sinfoは、Slurmが管理するパーティションとノードの状態を報告します。さまざまなフィルタリング、並べ替え、および書式設定オプションがあります。
sprio is used to display a detailed
view of the components affecting a job's priority.
sprioは、ジョブの優先度に影響を与えるコンポーネントの詳細ビューを表示するために使用されます。
squeue reports the state of jobs or
job steps. It has a wide variety of filtering, sorting, and formatting options.
By default, it reports the running jobs in priority order and then the pending
jobs in priority order.
squeueは、ジョブまたはジョブステップの状態を報告します。さまざまなフィルタリング、並べ替え、および書式設定オプションがあります。デフォルトでは、実行中のジョブを優先順位で報告し、保留中のジョブを優先順位で報告します。
srun is used to submit a job for
execution or initiate job steps in real time.
srun
has a wide variety of options to specify resource requirements, including: minimum
and maximum node count, processor count, specific nodes to use or not use, and
specific node characteristics (so much memory, disk space, certain required
features, etc.).
A job can contain multiple job steps executing sequentially or in parallel on
independent or shared resources within the job's node allocation.
srunは、実行のためにジョブを送信するか、リアルタイムでジョブステップを開始するために使用されます。srunには、最小および最大ノード数、プロセッサ数、使用または使用しない特定のノード、特定のノード特性(メモリ、ディスク容量、特定の必要な機能など)を含む、リソース要件を指定するさまざまなオプションがあります。 。ジョブには、ジョブのノード割り当て内の独立したリソースまたは共有リソース上で順次または並列に実行される複数のジョブステップを含めることができます。
sshare displays detailed information
about fairshare usage on the cluster. Note that this is only viable when using
the priority/multifactor plugin.
sshareは、クラスターでのフェアシェアの使用に関する詳細情報を表示します。これは、priority / multifactorプラグインを使用する場合にのみ実行可能であることに注意してください。
sstat is used to get information
about the resources utilized by a running job or job step.
sstatは、実行中のジョブまたはジョブステップによって利用されるリソースに関する情報を取得するために使用されます。
strigger is used to set, get or
view event triggers. Event triggers include things such as nodes going down
or jobs approaching their time limit.
striggerは、イベントトリガーを設定、取得、または表示するために使用されます。イベントトリガーには、ノードのダウンや、制限時間に近づいているジョブなどが含まれます。
sview is a graphical user interface to
get and update state information for jobs, partitions, and nodes managed by Slurm.
sviewは、Slurmが管理するジョブ、パーティション、ノードの状態情報を取得および更新するためのグラフィカルユーザーインターフェイスです。
Examples
First we determine what partitions exist on the system, what nodes
they include, and general system state. This information is provided
by the sinfo command.
In the example below we find there are two partitions: debug
and batch.
The * following the name debug indicates this is the
default partition for submitted jobs.
We see that both partitions are in an UP state.
Some configurations may include partitions for larger jobs
that are DOWN except on weekends or at night. The information
about each partition may be split over more than one line so that
nodes in different states can be identified.
In this case, the two nodes adev[1-2] are down.
The * following the state down indicate the nodes are
not responding. Note the use of a concise expression for node
name specification with a common prefix adev and numeric
ranges or specific numbers identified. This format allows for
very large clusters to be easily managed.
The sinfo command
has many options to easily let you view the information of interest
to you in whatever format you prefer.
See the man page for more information.
最初に、システムに存在するパーティション、それらに含まれるノード、および一般的なシステム状態を決定します。この情報は、sinfoコマンドによって提供されます。以下の例では、デバッグとバッチの2つのパーティションがあることがわかります。debugの名前に続く*は、これがサブミットされたジョブのデフォルトのパーティションであることを示します。両方のパーティションがUP状態にあることがわかります。一部の構成には、週末または夜を除いてダウンしているより大きなジョブのパーティションが含まれる場合があります。各パーティションに関する情報を複数の行に分割して、異なる状態のノードを識別できるようにすることができます。この場合、2つのノードadev [1-2]が停止しています。ダウン状態の後の*は、ノードが応答していないことを示します。共通の接頭辞adevと数値範囲または特定された特定の番号が指定されたノード名指定の簡潔な式の使用に注意してください。この形式では、非常に大きなクラスターを簡単に管理できます。sinfoコマンドには、目的の情報を好きな形式で簡単に表示するための多くのオプションがあります。詳細については、manページを参照してください。
adev0: sinfo PARTITION AVAIL TIMELIMIT NODES STATE NODELIST debug* up 30:00 2 down* adev[1-2] debug* up 30:00 3 idle adev[3-5] batch up 30:00 3 down* adev[6,13,15] batch up 30:00 3 alloc adev[7-8,14] batch up 30:00 4 idle adev[9-12]
Next we determine what jobs exist on the system using the
squeue command. The
ST field is job state.
Two jobs are in a running state (R is an abbreviation
for Running) while one job is in a pending state
(PD is an abbreviation for Pending).
The TIME field shows how long the jobs have run
for using the format days-hours:minutes:seconds.
The NODELIST(REASON) field indicates where the
job is running or the reason it is still pending. Typical
reasons for pending jobs are Resources (waiting
for resources to become available) and Priority
(queued behind a higher priority job).
The squeue command
has many options to easily let you view the information of interest
to you in whatever format you prefer.
See the man page for more information.
次に、squeueコマンドを使用して、システムに存在するジョブを判別します。STフィールドはジョブの状態です。2つのジョブは実行状態(RはRunningの略)であり、一方のジョブは保留状態(PDはPendingの略)です。TIMEフィールドは、日-時間:分:秒の形式でジョブが実行された時間を示します。NODELIST(REASON)フィールドは、ジョブが実行されている場所、またはジョブがまだ保留されている理由を示します。保留中のジョブの一般的な理由は、リソース(リソースが利用可能になるのを待つ)と優先度(優先度の高いジョブの背後にキューイングされる)です。squeueコマンドには、興味のある情報を好きな形式で簡単に表示するための多くのオプションがあります。詳細については、manページを参照してください。
adev0: squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 65646 batch chem mike R 24:19 2 adev[7-8] 65647 batch bio joan R 0:09 1 adev14 65648 batch math phil PD 0:00 6 (Resources)
The scontrol command
can be used to report more detailed information about
nodes, partitions, jobs, job steps, and configuration.
It can also be used by system administrators to make
configuration changes. A couple of examples are shown
below. See the man page for more information.
scontrolコマンドを使用して、ノード、パーティション、ジョブ、ジョブステップ、および構成に関する詳細情報を報告できます。また、システム管理者が構成を変更するために使用することもできます。いくつかの例を以下に示します。詳細については、manページを参照してください。
adev0: scontrol show partition PartitionName=debug TotalNodes=5 TotalCPUs=40 RootOnly=NO Default=YES OverSubscribe=FORCE:4 PriorityTier=1 State=UP MaxTime=00:30:00 Hidden=NO MinNodes=1 MaxNodes=26 DisableRootJobs=NO AllowGroups=ALL Nodes=adev[1-5] NodeIndices=0-4 PartitionName=batch TotalNodes=10 TotalCPUs=80 RootOnly=NO Default=NO OverSubscribe=FORCE:4 PriorityTier=1 State=UP MaxTime=16:00:00 Hidden=NO MinNodes=1 MaxNodes=26 DisableRootJobs=NO AllowGroups=ALL Nodes=adev[6-15] NodeIndices=5-14 adev0: scontrol show node adev1 NodeName=adev1 State=DOWN* CPUs=8 AllocCPUs=0 RealMemory=4000 TmpDisk=0 Sockets=2 Cores=4 Threads=1 Weight=1 Features=intel Reason=Not responding [slurm@06/02-14:01:24] 65648 batch math phil PD 0:00 6 (Resources) adev0: scontrol show job JobId=65672 UserId=phil(5136) GroupId=phil(5136) Name=math Priority=4294901603 Partition=batch BatchFlag=1 AllocNode:Sid=adev0:16726 TimeLimit=00:10:00 ExitCode=0:0 StartTime=06/02-15:27:11 EndTime=06/02-15:37:11 JobState=PENDING NodeList=(null) NodeListIndices= NumCPUs=24 ReqNodes=1 ReqS:C:T=1-65535:1-65535:1-65535 OverSubscribe=1 Contiguous=0 CPUs/task=0 Licenses=(null) MinCPUs=1 MinSockets=1 MinCores=1 MinThreads=1 MinMemory=0 MinTmpDisk=0 Features=(null) Dependency=(null) Account=(null) Requeue=1 Reason=None Network=(null) ReqNodeList=(null) ReqNodeListIndices= ExcNodeList=(null) ExcNodeListIndices= SubmitTime=06/02-15:27:11 SuspendTime=None PreSusTime=0 Command=/home/phil/math WorkDir=/home/phil
It is possible to create a resource allocation and launch
the tasks for a job step in a single command line using the
srun command. Depending
upon the MPI implementation used, MPI jobs may also be
launched in this manner.
See the MPI section for more MPI-specific information.
In this example we execute /bin/hostname
on three nodes (-N3) and include task numbers on the output (-l).
The default partition will be used.
One task per node will be used by default.
Note that the srun command has
many options available to control what resource are allocated
and how tasks are distributed across those resources.
srunコマンドを使用して、単一のコマンドラインでリソース割り当てを作成し、ジョブステップのタスクを起動することができます。使用するMPI実装によっては、MPIジョブもこの方法で起動できます。MPI固有の詳細については、MPIセクションを参照してください。この例では、3つのノードで/ bin / hostnameを実行し(-N3)、出力にタスク番号を含めます(-l)。デフォルトのパーティションが使用されます。ノードごとに1つのタスクがデフォルトで使用されます。srunコマンドには、割り当てられるリソースとそれらのリソースにタスクを分散する方法を制御するために使用できる多くのオプションがあることに注意してください。
adev0: srun -N3 -l /bin/hostname 0: adev3 1: adev4 2: adev5
This variation on the previous example executes
/bin/hostname in four tasks (-n4).
One processor per task will be used by default (note that we don't specify
a node count).
前の例のこのバリエーションは、4つのタスク(-n4)で/ bin / hostnameを実行します。タスクごとに1つのプロセッサがデフォルトで使用されます(ノード数は指定しないことに注意してください)。
adev0: srun -n4 -l /bin/hostname 0: adev3 1: adev3 2: adev3 3: adev3
One common mode of operation is to submit a script for later execution.
In this example the script name is my.script and we explicitly use
the nodes adev9 and adev10 (-w "adev[9-10]", note the use of a
node range expression).
We also explicitly state that the subsequent job steps will spawn four tasks
each, which will ensure that our allocation contains at least four processors
(one processor per task to be launched).
The output will appear in the file my.stdout ("-o my.stdout").
This script contains a timelimit for the job embedded within itself.
Other options can be supplied as desired by using a prefix of "#SBATCH" followed
by the option at the beginning of the script (before any commands to be executed
in the script).
Options supplied on the command line would override any options specified within
the script.
Note that my.script contains the command /bin/hostname
that executed on the first node in the allocation (where the script runs) plus
two job steps initiated using the srun command
and executed sequentially.
一般的な操作モードの1つは、後で実行するためにスクリプトを送信することです。この例では、スクリプト名はmy.scriptであり、ノードadev9およびadev10を明示的に使用しています(-w "adev [9-10]"、ノード範囲式の使用に注意)。また、後続のジョブステップでそれぞれ4つのタスクが生成されることを明示的に示します。これにより、割り当てに少なくとも4つのプロセッサが含まれるようになります(起動するタスクごとに1つのプロセッサ)。出力はファイルmy.stdout( "-o my.stdout")に表示されます。このスクリプトには、それ自体に埋め込まれたジョブの制限時間が含まれています。"#SBATCH"の接頭辞を使用し、その後にスクリプトの先頭(スクリプトで実行されるコマンドの前)にオプションを指定することで、必要に応じて他のオプションを指定できます。コマンドラインで指定されたオプションは、スクリプト内で指定されたオプションを上書きします。
adev0: cat my.script #!/bin/sh #SBATCH --time=1 /bin/hostname srun -l /bin/hostname srun -l /bin/pwd adev0: sbatch -n4 -w "adev[9-10]" -o my.stdout my.script sbatch: Submitted batch job 469 adev0: cat my.stdout adev9 0: adev9 1: adev9 2: adev10 3: adev10 0: /home/jette 1: /home/jette 2: /home/jette 3: /home/jette
The final mode of operation is to create a resource allocation
and spawn job steps within that allocation.
The salloc command is used
to create a resource allocation and typically start a shell within
that allocation.
One or more job steps would typically be executed within that allocation
using the srun command to launch the tasks
(depending upon the type of MPI being used, the launch mechanism may
differ, see MPI details below).
Finally the shell created by salloc would
be terminated using the exit command.
Slurm does not automatically migrate executable or data files
to the nodes allocated to a job.
Either the files must exists on local disk or in some global file system
(e.g. NFS or Lustre).
We provide the tool sbcast to transfer
files to local storage on allocated nodes using Slurm's hierarchical
communications.
In this example we use sbcast to transfer
the executable program a.out to /tmp/joe.a.out on local storage
of the allocated nodes.
After executing the program, we delete it from local storage
最後の操作モードは、リソース割り当てを作成し、その割り当て内にジョブステップを生成することです。sallocコマンドを使用してリソース割り当てを作成し、通常はその割り当て内でシェルを起動します。通常、1つ以上のジョブステップは、srunコマンドを使用してその割り当て内で実行され、タスクを起動します(使用されているMPIのタイプによって、起動メカニズムは異なる場合があります。以下のMPIの詳細を参照してください)。最後に、sallocによって作成されたシェルは、exitコマンドを使用して終了します。Slurmは、実行可能ファイルまたはデータファイルをジョブに割り当てられたノードに自動的に移行しません。ファイルはローカルディスクまたはグローバルファイルシステム(NFSまたはLustreなど)に存在する必要があります。Slurmの階層通信を使用して、割り当てられたノードのローカルストレージにファイルを転送するためのツールsbcastを提供します。この例では、sbcastを使用して、割り当てられたノードのローカルストレージ上の実行可能プログラムa.outを/tmp/joe.a.outに転送します。プログラムを実行した後、ローカルストレージから削除します
tux0: salloc -N1024 bash $ sbcast a.out /tmp/joe.a.out Granted job allocation 471 $ srun /tmp/joe.a.out Result is 3.14159 $ srun rm /tmp/joe.a.out $ exit salloc: Relinquishing job allocation 471
In this example, we submit a batch job, get its status, and cancel it.
この例では、バッチジョブを送信し、そのステータスを取得してキャンセルします。
adev0: sbatch test srun: jobid 473 submitted adev0: squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 473 batch test jill R 00:00 1 adev9 adev0: scancel 473 adev0: squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
Best Practices, Large Job Counts
Consider putting related work into a single Slurm job with multiple job
steps both for performance reasons and ease of management.
Each Slurm job can contain a multitude of job steps and the overhead in
Slurm for managing job steps is much lower than that of individual jobs.
パフォーマンス上の理由と管理の容易さの両方のために、関連する作業を複数のジョブステップを持つ単一のSlurmジョブに入れることを検討してください。各Slurmジョブには多数のジョブステップを含めることができ、ジョブステップを管理するためのSlurmのオーバーヘッドは、個々のジョブのオーバーヘッドよりもはるかに低くなります。
Job arrays are an efficient mechanism of
managing a collection of batch jobs with identical resource requirements.
Most Slurm commands can manage job arrays either as individual elements (tasks)
or as a single entity (e.g. delete an entire job array in a single command).
ジョブ配列は、同一のリソース要件を持つバッチジョブのコレクションを管理する効率的なメカニズムです。ほとんどのSlurmコマンドは、個別の要素(タスク)または単一のエンティティ(たとえば、単一のコマンドでジョブ配列全体を削除する)としてジョブ配列を管理できます。
MPI
MPI use depends upon the type of MPI being used.
There are three fundamentally different modes of operation used
by these various MPI implementation.
MPIの使用は、使用するMPIのタイプによって異なります。これらのさまざまなMPI実装で使用される基本的に異なる3つの動作モードがあります。
- Slurm directly launches the tasks and performs initialization of
communications through the PMI2 or PMIx APIs. (Supported by most
modern MPI implementations.)
Slurmはタスクを直接起動し、PMI2またはPMIx APIを介して通信の初期化を実行します。(最新のMPI実装でサポートされています。) - Slurm creates a resource allocation for the job and then
mpirun launches tasks using Slurm's infrastructure (older versions of
OpenMPI).
Slurmはジョブのリソース割り当てを作成し、mpirunはSlurmのインフラストラクチャ(古いバージョンのOpenMPI)を使用してタスクを起動します。 - Slurm creates a resource allocation for the job and then
mpirun launches tasks using some mechanism other than Slurm,
such as SSH or RSH.
These tasks initiated outside of Slurm's monitoring
or control. Slurm's epilog should be configured to purge
these tasks when the job's allocation is relinquished. The
use of pam_slurm_adopt is also strongly recommended.
Slurmはジョブのリソース割り当てを作成し、mpirunはSSHやRSHなどのSlurm以外のメカニズムを使用してタスクを起動します。これらのタスクは、Slurmの監視または制御の外部で開始されました。Slurmのエピローグは、ジョブの割り当てが放棄されたときにこれらのタスクをパージするように構成する必要があります。pam_slurm_adoptの使用も強く推奨されます。
Links to instructions for using several varieties of MPI
with Slurm are provided below.
Slurmでいくつかの種類のMPIを使用するための手順へのリンクを以下に示します。
Last modified 19 November 2019