Overview
Slurm is an open source,
fault-tolerant, and highly scalable cluster management and job scheduling system
for large and small Linux clusters. Slurm requires no kernel modifications for
its operation and is relatively self-contained. As a cluster workload manager,
Slurm has three key functions. First, it allocates exclusive and/or non-exclusive
access to resources (compute nodes) to users for some duration of time so they
can perform work. Second, it provides a framework for starting, executing, and
monitoring work (normally a parallel job) on the set of allocated nodes.
Finally, it arbitrates contention for resources by managing a queue of
pending work.
Optional plugins can be used for
accounting,
advanced reservation,
gang scheduling (time sharing for
parallel jobs), backfill scheduling,
topology optimized resource selection,
resource limits by user or bank account,
and sophisticated multifactor job
prioritization algorithms.
Slurmは、オープンソースで、フォールトトレラントで、スケーラブルなクラスター管理と、大小のLinuxクラスター向けのジョブスケジューリングシステムです。Slurmは操作にカーネルの変更を必要とせず、比較的自己完結型です。クラスターワークロードマネージャーとして、Slurmには3つの主要な機能があります。まず、ユーザーが作業を実行できるように、リソース(計算ノード)への排他的および/または非排他的アクセスを一定期間ユーザーに割り当てます。次に、割り当てられたノードのセットで作業(通常は並列ジョブ)を開始、実行、および監視するためのフレームワークを提供します。最後に、保留中の作業のキューを管理することにより、リソースの競合を調停します。オプションのプラグインは、アカウンティング、事前予約、ギャングスケジューリング(並列ジョブのタイムシェアリング)、バックフィルスケジューリング、トポロジー最適化リソース選択、
Architecture
Slurm has a centralized manager, slurmctld, to monitor resources and
work. There may also be a backup manager to assume those responsibilities in the
event of failure. Each compute server (node) has a slurmd daemon, which
can be compared to a remote shell: it waits for work, executes that work, returns
status, and waits for more work.
Slurmには、リソースと作業を監視するための集中管理マネージャーslurmctldがあります。障害が発生した場合にこれらの責任を負うバックアップマネージャーが存在する場合もあります。各計算サーバー(ノード)にはslurmdデーモンがあり、リモートシェルと比較できます。それは、作業を待機し、その作業を実行し、ステータスを返し、さらに作業を待機します。
The slurmd daemons provide fault-tolerant hierarchical communications.
There is an optional slurmdbd (Slurm DataBase Daemon) which can be used
to record accounting information for multiple Slurm-managed clusters in a
single database.
slurmdデーモンは、フォールトトレラントな階層型通信を提供します。オプションのslurmdbd(Slurm DataBase Daemon)があり、単一のデータベースで複数のSlurm管理クラスターのアカウンティング情報を記録するために使用できます。
There is an optional
slurmrestd (Slurm REST API Daemon)
which can be used to interact with Slurm through its
REST API.
REST APIを介してSlurmと対話するために使用できるオプションのslurmrestd(Slurm REST APIデーモン)があります。
User tools include srun to initiate jobs,
scancel to terminate queued or running jobs,
sinfo to report system status,
squeue to report the status of jobs, and
sacct to get information about jobs and job steps that are running or have completed.
ユーザーツールには、ジョブを開始するsrun、待機中または実行中のジョブを終了するscancel、システムステータスを報告するsinfo、ジョブのステータスを報告するsqueue、実行中または完了したジョブおよびジョブステップに関する情報を取得するsacctが含まれます。
The sview commands graphically reports system and
job status including network topology.
There is an administrative tool scontrol available to monitor
and/or modify configuration and state information on the cluster.
The administrative tool used to manage the database is sacctmgr.
It can be used to identify the clusters, valid users, valid bank accounts, etc.
APIs are available for all functions.
sviewコマンドは、ネットワークトポロジを含むシステムとジョブのステータスをグラフィカルに報告します。クラスターの構成および状態情報を監視および/または変更するために使用できる管理ツールscontrolがあります。データベースの管理に使用される管理ツールはsacctmgrです。クラスター、有効なユーザー、有効な銀行口座などを識別するために使用できます。APIはすべての機能で使用できます。
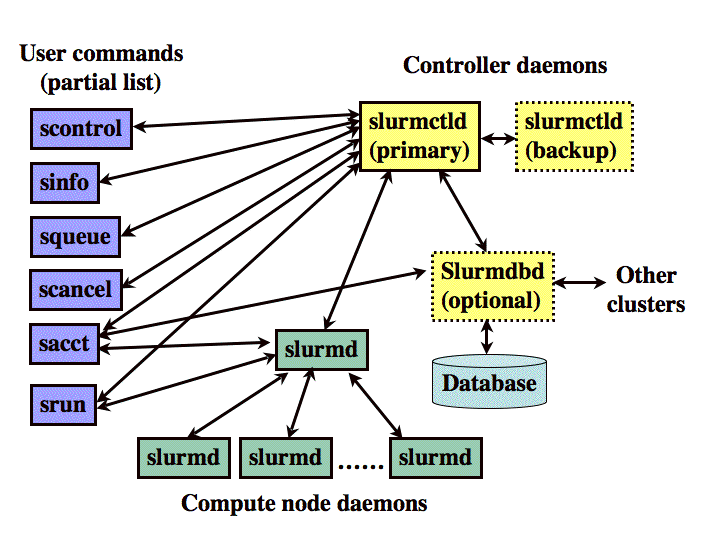
Figure 1. Slurm components
Slurm has a general-purpose plugin mechanism available to easily support various
infrastructures. This permits a wide variety of Slurm configurations using a
building block approach. These plugins presently include:
Slurmには、さまざまなインフラストラクチャを簡単にサポートできる汎用プラグインメカニズムがあります。これにより、ビルディングブロックアプローチを使用したさまざまなSlurm構成が可能になります。これらのプラグインには現在、次のものが含まれます。
- Accounting Storage:
Primarily Used to store historical data about jobs. When used with
SlurmDBD (Slurm Database Daemon), it can also supply a
limits based system along with historical system status.
アカウンティングストレージ:主に、ジョブに関する履歴データを保存するために使用されます。SlurmDBD(Slurm Database Daemon)とともに使用すると、履歴ベースのシステムステータスとともに制限ベースのシステムを提供できます。
- Account Gather Energy:
Gather energy consumption data per job or nodes in the system.
This plugin is integrated with the
Accounting Storage and
Job Account Gather plugins.
アカウントエネルギーの収集:システム内のジョブまたはノードごとのエネルギー消費データを収集します。このプラグインは、Accounting StorageおよびJob Account Gatherプラグインと統合されています。
- Authentication of communications:
Provides authentication mechanism between various components of Slurm.
通信の認証:Slurmのさまざまなコンポーネント間の認証メカニズムを提供します。
- Containers:
HPC workload container support and implementations.
コンテナー:HPCワークロードコンテナーのサポートと実装。
- Credential (Digital Signature
Generation):
Mechanism used to generate a digital signature, which is used to validate
that job step is authorized to execute on specific nodes.
This is distinct from the plugin used for
Authentication since the job step
request is sent from the user's srun command rather than directly from the
slurmctld daemon, which generates the job step credential and its
digital signature.
資格情報(デジタル署名の生成):デジタル署名の生成に使用されるメカニズム。ジョブステップが特定のノードでの実行を承認されていることを検証するために使用されます。ジョブステップのリクエストは、ジョブステップの認証情報とそのデジタル署名を生成するslurmctldデーモンから直接送信されるのではなく、ユーザーのsrunコマンドから送信されるため、これは認証に使用されるプラグインとは異なります。
- Generic Resources: Provide interface to
control generic resources like Processing Units (GPUs) and Intel®
Many Integrated Core (MIC) processors.
汎用リソース:プロセッシングユニット(GPU)やIntel®Many Integrated Core(MIC)プロセッサーなどの汎用リソースを制御するためのインターフェイスを提供します。
- Job Submit:
Custom plugin to allow site specific control over job requirements at
submission and update.
ジョブ送信:送信および更新時にジョブ要件をサイト固有に制御できるカスタムプラグイン。
- Job Accounting Gather:
Gather job step resource utilization data.
Job Accounting Gather:ジョブステップのリソース使用率データを収集します。
- Job Completion Logging:
Log a job's termination data. This is typically a subset of data stored by
an Accounting Storage Plugin.
ジョブ完了ロギング:ジョブの終了データをログに記録します。これは通常、アカウンティングストレージプラグインによって格納されるデータのサブセットです。
- Launchers:
Controls the mechanism used by the 'srun' command
to launch the tasks.
ランチャー:「srun」コマンドがタスクを起動するために使用するメカニズムを制御します。
- MPI:
Provides different hooks for the various MPI implementations.
For example, this can set MPI specific environment variables.
MPI:さまざまなMPI実装に異なるフックを提供します。たとえば、MPI固有の環境変数を設定できます。
- Preempt:
Determines which jobs can preempt other jobs and the preemption mechanism
to be used.
プリエンプション:他のジョブをプリエンプトできるジョブと、使用するプリエンプションメカニズムを決定します。
- Priority:
Assigns priorities to jobs upon submission and on an ongoing basis
(e.g. as they age).
優先度:提出時および継続的に(たとえば、年齢に応じて)ジョブに優先度を割り当てます。
- Process tracking (for signaling):
Provides a mechanism for identifying the processes associated with each job.
Used for job accounting and signaling.
プロセス追跡(シグナリング用):各ジョブに関連付けられているプロセスを識別するメカニズムを提供します。ジョブアカウンティングとシグナリングに使用されます。
- Scheduler:
Plugin determines how and when Slurm schedules jobs.
スケジューラー:プラグインは、Slurmがジョブをスケジュールする方法とタイミングを決定します。
- Node selection:
Plugin used to determine the resources used for a job allocation.
ノードの選択:ジョブの割り当てに使用されるリソースを決定するために使用されるプラグイン。
- Site Factor (Priority):
Assigns a specific site_factor component of a job's multifactor priority to
jobs upon submission and on an ongoing basis (e.g. as they age).
サイトファクター(優先度):ジョブのマルチファクター優先度の特定のsite_factorコンポーネントを、送信時および継続的に(たとえば、ジョブが古くなるにつれて)ジョブに割り当てます。
- Switch or interconnect:
Plugin to interface with a switch or interconnect.
For most systems (ethernet or infiniband) this is not needed.
スイッチまたは相互接続:スイッチまたは相互接続とインターフェースするプラグイン。ほとんどのシステム(イーサネットまたはinfiniband)では、これは必要ありません。
- Task Affinity:
Provides mechanism to bind a job and its individual tasks to specific
processors.
タスクアフィニティ:ジョブとその個々のタスクを特定のプロセッサにバインドするメカニズムを提供します。
- Network Topology:
Optimizes resource selection based upon the network topology.
Used for both job allocations and advanced reservation.
ネットワークトポロジ:ネットワークトポロジに基づいてリソースの選択を最適化します。ジョブの割り当てと事前予約の両方に使用されます。
The entities managed by these Slurm daemons, shown in Figure 2, include nodes,
the compute resource in Slurm, partitions, which group nodes into logical
sets, jobs, or allocations of resources assigned to a user for
a specified amount of time, and job steps, which are sets of (possibly
parallel) tasks within a job.
これらのSlurmデーモンによって管理されるエンティティには、図2に示すように、ノード、Slurmのコンピューティングリソース、パーティション、ノードを論理セット、ジョブ、または指定された時間ユーザーに割り当てられたリソースの割り当てにグループ化したものが含まれます。ステップは、ジョブ内の(場合によっては並列の)タスクのセットです。
The partitions can be considered job queues, each of which has an assortment of
constraints such as job size limit, job time limit, users permitted to use it, etc.
Priority-ordered jobs are allocated nodes within a partition until the resources
(nodes, processors, memory, etc.) within that partition are exhausted. Once
a job is assigned a set of nodes, the user is able to initiate parallel work in
the form of job steps in any configuration within the allocation. For instance,
a single job step may be started that utilizes all nodes allocated to the job,
or several job steps may independently use a portion of the allocation.
パーティションはジョブキューと見なすことができ、それぞれにジョブサイズの制限、ジョブの時間制限、使用を許可されたユーザーなどのさまざまな制約があります。優先順位付けされたジョブは、リソース(ノード、そのパーティション内のプロセッサ、メモリなど)が使い果たされています。ジョブにノードのセットが割り当てられると、ユーザーは割り当て内の任意の構成でジョブステップの形式で並列作業を開始できます。たとえば、ジョブに割り当てられたすべてのノードを利用する単一のジョブステップを開始したり、いくつかのジョブステップで割り当ての一部を独立して使用したりできます。
Slurm provides resource management for the processors allocated to a job,
so that multiple job steps can be simultaneously submitted and queued until
there are available resources within the job's allocation.
Slurmは、ジョブに割り当てられたプロセッサのリソース管理を提供するため、ジョブの割り当て内に使用可能なリソースができるまで、複数のジョブステップを同時に送信してキューに入れることができます。
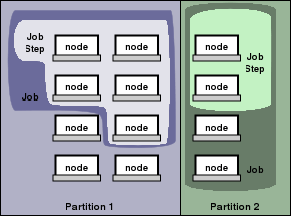
Figure 2. Slurm entities
Configurability
Node state monitored include: count of processors, size of real memory, size
of temporary disk space, and state (UP, DOWN, etc.). Additional node information
includes weight (preference in being allocated work) and features (arbitrary information
such as processor speed or type).
監視されるノードの状態には、プロセッサの数、実メモリのサイズ、一時ディスク領域のサイズ、および状態(UP、DOWNなど)が含まれます。追加のノード情報には、重み(割り当てられた作業の優先度)と機能(プロセッサの速度やタイプなどの任意の情報)が含まれます。
Nodes are grouped into partitions, which may contain overlapping nodes so they are
best thought of as job queues.
ノードはパーティションにグループ化されます。パーティションには重複するノードが含まれる可能性があるため、ジョブキューと考えるのが最適です。
Partition information includes: name, list of associated nodes, state (UP or DOWN),
maximum job time limit, maximum node count per job, group access list,
priority (important if nodes are in multiple partitions) and shared node access policy
with optional over-subscription level for gang scheduling (e.g. YES, NO or FORCE:2).
パーティション情報には、名前、関連ノードのリスト、状態(UPまたはDOWN)、最大ジョブ時間制限、ジョブごとの最大ノード数、グループアクセスリスト、優先度(ノードが複数のパーティションにある場合に重要)、およびオプションの共有ノードアクセスポリシーが含まれます。ギャングスケジューリングのオーバーサブスクリプションレベル(例:YES、NOまたはFORCE:2)。
Bit maps are used to represent nodes and scheduling
decisions can be made by performing a small number of comparisons and a series
of fast bit map manipulations. A sample (partial. Slurm configuration file follows.
ノードを表すためにビットマップが使用され、少数の比較と一連の高速ビットマップ操作を実行することで、スケジューリングの決定を行うことができます。サンプル(部分的。Slurm構成ファイルが続きます。
# # Sample /etc/slurm.conf # SlurmctldHost=linux0001 # Primary server SlurmctldHost=linux0002 # Backup server # AuthType=auth/munge Epilog=/usr/local/slurm/sbin/epilog PluginDir=/usr/local/slurm/lib Prolog=/usr/local/slurm/sbin/prolog SlurmctldPort=7002 SlurmctldTimeout=120 SlurmdPort=7003 SlurmdSpoolDir=/var/tmp/slurmd.spool SlurmdTimeout=120 StateSaveLocation=/usr/local/slurm/slurm.state TmpFS=/tmp # # Node Configurations # NodeName=DEFAULT CPUs=4 TmpDisk=16384 State=IDLE NodeName=lx[0001-0002] State=DRAINED NodeName=lx[0003-8000] RealMemory=2048 Weight=2 NodeName=lx[8001-9999] RealMemory=4096 Weight=6 Feature=video # # Partition Configurations # PartitionName=DEFAULT MaxTime=30 MaxNodes=2 PartitionName=login Nodes=lx[0001-0002] State=DOWN PartitionName=debug Nodes=lx[0003-0030] State=UP Default=YES PartitionName=class Nodes=lx[0031-0040] AllowGroups=students PartitionName=DEFAULT MaxTime=UNLIMITED MaxNodes=4096 PartitionName=batch Nodes=lx[0041-9999]
Last modified 7 Februrary 2020