Classic Fairshare Algorithm
Overview
As of the 19.05 release, the Fair Tree algorithm is now the default, and the
classic fair share algorithm is only available if
PriorityFlags=NO_FAIR_TREE has been explicitly configured.
19.05リリース以降、フェアツリーアルゴリズムがデフォルトになり、クラシックフェアシェアアルゴリズムは、PriorityFlags = NO_FAIR_TREEが明示的に構成されている場合にのみ使用できます。
Normalized Shares
The fair-share hierarchy represents the portion of the computing resources
that have been allocated to different projects. These allocations are assigned
to an account. There can be multiple levels of allocations made as allocations
of a given account are further divided to sub-accounts:
フェアシェア階層は、さまざまなプロジェクトに割り当てられているコンピューティングリソースの部分を表します。これらの割り当ては、アカウントに割り当てられます。特定のアカウントの割り当てがサブアカウントにさらに分割されるため、複数のレベルの割り当てを行うことができます。
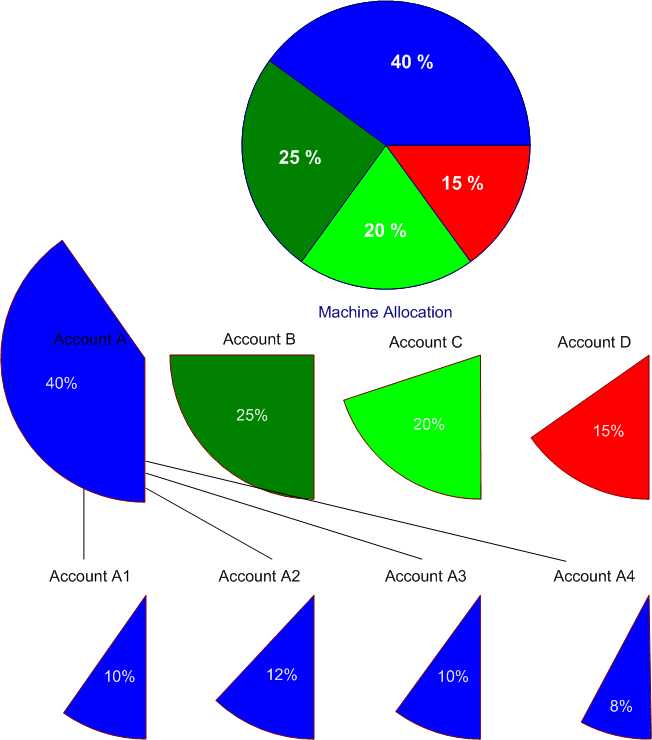
Figure 1. Machine Allocation
The chart above shows the resources of the machine allocated to four
accounts: A, B, C and D. Furthermore, account A's shares are allocated to
sub-accounts A1 through A4. Users are granted permission (through sacctmgr) to
submit jobs against specific accounts. If there are 10 users given equal shares
in Account A3, they will each be allocated 1% of the machine.
上のグラフは、A、B、C、Dの4つのアカウントに割り当てられたマシンのリソースを示しています。さらに、アカウントAのシェアはサブアカウントA1からA4に割り当てられています。ユーザーには、(sacctmgrを介して)特定のアカウントに対してジョブを送信する権限が付与されます。アカウントA3に等しいシェアが与えられている10人のユーザーがいる場合、それぞれにマシンの1%が割り当てられます。
A user's normalized shares are simply:
ユーザーの正規化されたシェアは単純です:
S = (Suser / Ssiblings) * (Saccount / Ssibling-accounts) * (Sparent / Sparent-siblings) * ...Where:
- S
- is the user's normalized share, between zero and one
0と1の間のユーザーの正規化されたシェアのSis
- Suser
- are the number of shares of the account allocated to the user
Suserareユーザーに割り当てられたアカウントのシェア数
- Ssiblings
- are the total number of shares allocated to all users permitted to charge the account (including Suser)
Ssiblingsは、アカウントへの課金を許可されているすべてのユーザー(Suserを含む)に割り当てられた共有の総数です
- Saccount
- are the number of shares of the parent account allocated to the account
Saccountは、アカウントに割り当てられた親アカウントの株式数です
- Ssibling-accounts
- are the total number of shares allocated to all sub-accounts of the parent account
兄弟アカウントは、親アカウントのすべてのサブアカウントに割り当てられたシェアの総数です
- Sparent
- are the number of shares of the grandparent account allocated to the parent
Sparentareは、親に割り当てられた祖父母の口座の株数
- Sparent-siblings
- are the total number of shares allocated to all sub-accounts of the grandparent account
親兄弟は、祖父母アカウントのすべてのサブアカウントに割り当てられた共有の総数です
Normalized Usage
The processor*seconds allocated to every job are tracked in real-time. If one only considered usage over a fixed time period, then calculating a user's normalized usage would be a simple quotient:
すべてのジョブに割り当てられたプロセッサ*秒は、リアルタイムで追跡されます。一定期間の使用量のみを考慮した場合、ユーザーの正規化された使用量の計算は単純な商になります。
UN = Uuser / UtotalWhere:
- UN
- is normalized usage, between zero and one
UNは、0〜1の正規化された使用法です。
- Uuser
- is the processor*seconds consumed by all of a user's jobs in a given account for over a fixed time period
Uuserは、特定のアカウント内のユーザーのすべてのジョブによって一定期間にわたって消費されたプロセッサ*秒
- Utotal
- is the total number of processor*seconds utilized across the cluster during that same time period
Utotalは、同じ期間中にクラスター全体で使用されたプロセッサー*秒の合計数です
However, significant real-world usage quantities span multiple time periods. Rather than treating usage over a number of weeks or months with equal importance, Slurm's fair-share priority calculation places more importance on the most recent resource usage and less importance on usage from the distant past.
ただし、実際の重要な使用量は複数の期間に及びます。数週間または数か月にわたる使用量を同等の重要度で扱うのではなく、Slurmのフェアシェア優先度計算では、最新のリソース使用量を重視し、遠い過去の使用量を重視しません。
The Slurm usage metric is based off a half-life formula that favors the most recent usage statistics. Usage statistics from the past decrease in importance based on a single decay factor, D:
Slurm使用メトリックは、最新の使用統計を支持する半減期の式に基づいています。過去の使用統計は、単一の減衰係数Dに基づいて重要度が低下しています。
UH = Ucurrent_period + ( D * Ulast_period) + (D * D * Uperiod-2) + ...Where:
- UH
- is the historical usage subject to the half-life decay
UHisは、半減期の減衰の影響を受ける歴史的な使用法です。
- Ucurrent_period
- is the usage charged over the current measurement period
Ucurrent_periodis現在の測定期間中に請求された使用量
- Ulast_period
- is the usage charged over the last measurement period
Ulast_periodisは、最後の測定期間に請求された使用量
- Uperiod-2
- is the usage charged over the second last measurement period
Uperiod-2は、2番目の最後の測定期間中に請求された使用量です。
- D
- is a decay factor between zero and one that delivers the
half-life decay based off the PriorityDecayHalfLife setting
in the slurm.conf file. Without accruing additional usage, a user's
UH usage will decay to half its original value after a time period
of PriorityDecayHalfLife seconds.
slurm.confファイルのPriorityDecayHalfLife設定に基づいて、半減期の減衰を実現するゼロと1の間の減衰係数を表示します。追加の使用量が発生しない場合、ユーザーのUH使用量は、PriorityDecayHalfLife秒の時間が経過すると、元の値の半分に減衰します。
In practice, the PriorityDecayHalfLife could be a matter of
seconds or days as appropriate for each site. The decay is
recalculated every PriorityCalcPeriod minutes, or 5 minutes by
default. The decay factor, D, is assigned the value that will achieve
the half-life decay rate specified by the PriorityDecayHalfLife
parameter.
実際には、PriorityDecayHalfLifeは、各サイトに応じて数秒から数日になる可能性があります。減衰は、PriorityCalcPeriod分ごと、またはデフォルトでは5分ごとに再計算されます。減衰係数Dには、PriorityDecayHalfLifeパラメーターで指定された半減期の減衰率を達成する値が割り当てられます。
The total number of processor*seconds utilized can be similarly aggregated with the same decay factor:
使用されるプロセッサー*秒の合計数は、同じ減衰係数で同様に集計できます。
RH = Rcurrent_period + ( D * Rlast_period) + (D * D * Rperiod-2) + ...Where:
- RH
- is the total historical usage subject to the same half-life decay as the usage formula.
RHは、使用量の計算式と同じ半減期減衰の対象となる過去の使用量の合計です。
- Rcurrent_period
- is the total usage charged over the current measurement period
Rcurrent_periodis現在の測定期間中に請求された総使用量
- Rlast_period
- is the total usage charged over the last measurement period
Rlast_periodisは、最後の測定期間中に請求された合計使用量
- Rperiod-2
- is the total usage charged over the second last measurement period
Rperiod-2は、2番目の最後の測定期間中に請求された合計使用量です。
- D
- is the decay factor between zero and one
ゼロと1の間の減衰係数をディス
A user's normalized usage that spans multiple time periods then becomes:
複数の期間にわたるユーザーの正規化された使用量は次のようになります。
U = UH / RH
Simplified Fair-Share Formula
The simplified formula for calculating the fair-share factor for usage that spans multiple time periods and subject to a half-life decay is:
複数の期間にまたがり、半減期の減衰の影響を受ける使用のフェアシェア係数を計算するための簡略化された式は次のとおりです。
F = 2**(-U/S/d)Where:
- F
- is the fair-share factor
Fiのフェアシェア係数
- S
- is the normalized shares
正規化されたシェアのSis
- U
- is the normalized usage factoring in half-life decay
Uiは、半減期減衰における因数分解の正規化です。
- d
- is the FairShareDampeningFactor (a configuration parameter, default value of 1)
FairShareDampeningFactor(構成パラメーター、デフォルト値は1)
The fair-share factor will therefore range from zero to one, where one represents the highest priority for a job. A fair-share factor of 0.5 indicates that the user's jobs have used exactly the portion of the machine that they have been allocated. A fair-share factor of above 0.5 indicates that the user's jobs have consumed less than their allocated share while a fair-share factor below 0.5 indicates that the user's jobs have consumed more than their allocated share of the computing resources.
したがって、フェアシェア係数は0から1の範囲であり、1はジョブの最高の優先順位を表します。フェアシェア係数0.5は、ユーザーのジョブが割り当てられたマシンの部分を正確に使用したことを示します。0.5を超えるフェアシェア係数は、ユーザーのジョブが割り当てられたシェアよりも少ない量を消費したことを示し、0.5未満のフェアシェア係数は、ユーザーのジョブがコンピューティングリソースの割り当てられたシェアを超えて消費したことを示します。
The Fair-share Factor Under An Account Hierarchy
The method described above presents a system whereby the priority of a user's job is calculated based on the portion of the machine allocated to the user and the historical usage of all the jobs run by that user under a specific account.
上記の方法は、ユーザーのジョブの優先順位が、ユーザーに割り当てられたマシンの部分と、特定のアカウントでそのユーザーが実行したすべてのジョブの履歴使用量に基づいて計算されるシステムを示しています。
Another layer of "fairness" is necessary however, one that factors in the usage of other users drawing from the same account. This allows a job's fair-share factor to be influenced by the computing resources delivered to jobs of other users drawing from the same account.
ただし、「公平性」のもう1つの層が必要です。この層は、同じアカウントから他のユーザーの使用を考慮します。これにより、ジョブのフェアシェア要素が、同じアカウントから他のユーザーのジョブに配信されるコンピューティングリソースの影響を受けるようになります。
If there are two members of a given account, and if one of those users has run many jobs under that account, the job priority of a job submitted by the user who has not run any jobs will be negatively affected. This ensures that the combined usage charged to an account matches the portion of the machine that is allocated to that account.
特定のアカウントに2つのメンバーがあり、それらのユーザーの1人がそのアカウントで多くのジョブを実行している場合、ジョブを実行していないユーザーが送信したジョブのジョブ優先順位は悪影響を受けます。これにより、アカウントに請求された合計使用量が、そのアカウントに割り当てられているマシンの部分と確実に一致します。
In the example below, when user 3 submits their first job using account C, they will want their job's priority to reflect all the resources delivered to account B. They do not care that user 1 has been using up a significant portion of the cycles allocated to account B and user 2 has yet to run a job out of account B. If user 2 submits a job using account B and user 3 submits a job using account C, user 3 expects their job to be scheduled before the job from user 2.
以下の例では、ユーザー3がアカウントCを使用して最初のジョブを送信すると、アカウントBに配信されたすべてのリソースがジョブの優先順位に反映されます。ユーザー1が割り当てられたサイクルのかなりの部分を使い切ったことは気にしません。アカウントBへ、ユーザー2はまだアカウントBからジョブを実行していません。ユーザー2がアカウントBを使用してジョブを送信し、ユーザー3がアカウントCを使用してジョブを送信した場合、ユーザー3はユーザー2からのジョブの前にジョブがスケジュールされることを期待します。
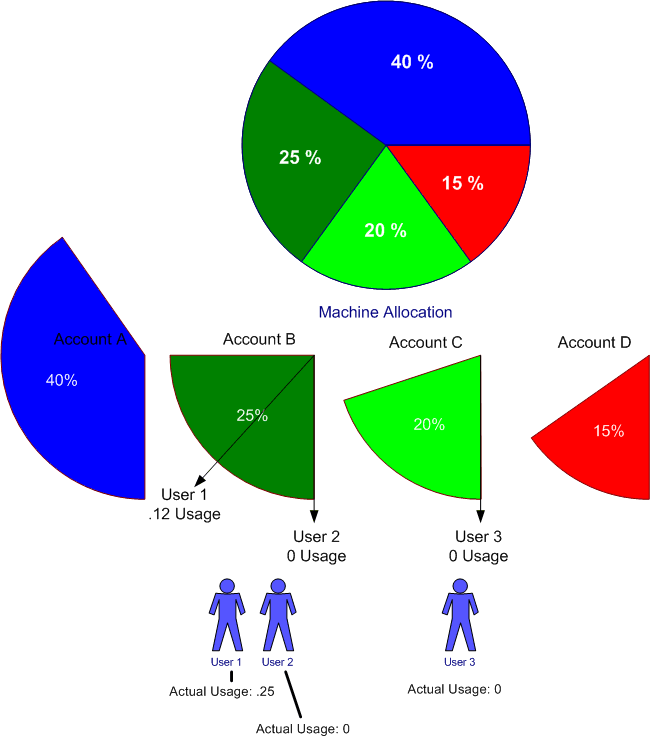
Figure 2. Usage Example
The Slurm Fair-Share Formula
The Slurm fair-share formula has been designed to provide fair scheduling to users based on the allocation and usage of every account.
Slurmのフェアシェア方式は、すべてのアカウントの割り当てと使用に基づいてユーザーに公平なスケジューリングを提供するように設計されています。
The actual formula used is a refinement of the formula presented above:
使用される実際の式は、上記の式を改良したものです。
F = 2**(-UE/S)
The difference is that the usage term is effective usage, which is defined as:
違いは、使用法の用語が有効な使用法であり、次のように定義されることです。
UE = UAchild + ((UEparent - UAchild) * Schild/Sall_siblings)Where:
- UE
- is the effective usage of the child user or child account
UEは、子ユーザーまたは子アカウントの効果的な使用法です。
- UAchild
- is the actual usage of the child user or child account
UAchildは、子ユーザーまたは子アカウントの実際の使用法です
- UEparent
- is the effective usage of the parent account
UEparentisは親アカウントの効果的な使用法
- Schild
- is the shares allocated to the child user or child account
Schildは、子ユーザーまたは子アカウントに割り当てられた共有です
- Sall_siblings
- is the shares allocated to all the children of the parent account
Sall_siblingsis親アカウントのすべての子に割り当てられたシェア
This formula only applies with the second tier of accounts below root. For the tier of accounts just under root, their effective usage equals their actual usage.
この式は、ルートの下の2番目の層のアカウントにのみ適用されます。ルート直下のアカウントの階層では、それらの有効使用量は実際の使用量と等しくなります。
Because the formula for effective usage includes a term of the effective usage of the parent, the calculation for each account in the tree must start at the second tier of accounts and proceed downward: to the children accounts, then grandchildren, etc. The effective usage of the users will be the last to be calculated.
有効使用量の式には親の有効使用量の項が含まれているため、ツリー内の各アカウントの計算は、アカウントの第2層から開始し、下に進む必要があります。子アカウント、次に孫などに進みます。ユーザーの最後に計算されます。
Plugging in the effective usage into the fair-share formula above yields a fair-share factor that reflects the aggregated usage charged to each of the accounts in the fair-share hierarchy.
上記のフェアシェアの式に有効使用量を組み込むと、フェアシェア階層の各アカウントに課金される使用量の合計を反映するフェアシェア係数が得られます。
FairShare=parent
It is possible to disable the fairshare at certain levels of the fair share
hierarchy by using the FairShare=parent option of sacctmgr.
For users and accounts with FairShare=parent the normalized shares
and effective usage values from the parent in the hierarchy will be used when
calculating fairshare priories.
sacctmgrのFairShare = parentオプションを使用すると、フェアシェア階層の特定のレベルでフェアシェアを無効にすることができます。FairShare = parentのユーザーとアカウントの場合、フェアシェアの優先順位を計算するときに、階層内の親からの正規化されたシェアと有効使用量の値が使用されます。
If all users in an account are configured with FairShare=parent
the result is that all the jobs drawing from that account will get the same
fairshare priority, based on the accounts total usage. No additional fairness
is added based on a user's individual usage.
アカウント内のすべてのユーザーがFairShare = parentで構成されている場合、そのアカウントからのすべてのジョブは、アカウントの合計使用量に基づいて、同じフェアシェア優先順位を取得します。ユーザーの個々の使用に基づいて、追加の公平性が追加されることはありません。
Example
The following example demonstrates the effective usage calculations and resultant fair-share factors. (See Figure 3 below.)
次の例は、効果的な使用量の計算と、結果として生じるフェアシェア係数を示しています。(下の図3を参照してください。)
The machine's computing resources are allocated to accounts A and D with 40 and 60 shares respectively. Account A is further divided into two children accounts, B with 30 shares and C with 10 shares. Account D is further divided into two children accounts, E with 25 shares and F with 35 shares.
マシンのコンピューティングリソースは、それぞれ40と60のシェアを持つアカウントAとDに割り当てられます。アカウントAは2つの子アカウントにさらに分割されます。Bは30株、Cは10株です。アカウントDはさらに2つの子アカウントに分けられ、Eは25株、Fは35株です。
Note: the shares at any given tier in the Account hierarchy do not need to total up to 100 shares. This example shows them totaling up to 100 to make the arithmetic easier to follow in your head.
注:アカウント階層内の任意の階層のシェアは、合計で最大100である必要はありません。この例は、それらが合計で100になることを示しており、計算が頭の中でわかりやすくなっています。
User 1 is granted permission to submit jobs against the B account. Users 2 and 3 are granted one share each in the C account. User 4 is the sole member of the E account and User 5 is the sole member of the F account.
ユーザー1には、Bアカウントに対してジョブを送信する権限が付与されています。ユーザー2と3には、Cアカウントでそれぞれ1つの共有が付与されます。ユーザー4はEアカウントの唯一のメンバーであり、ユーザー5はFアカウントの唯一のメンバーです。
Note: accounts A and D do not have any user members in this example, though users could have been assigned.
注:この例では、アカウントAとDにはユーザーメンバーがありませんが、ユーザーが割り当てられている可能性があります。
The shares assigned to each account make it easy to determine normalized
shares of the machine's complete resources. Account A has .4 normalized shares,
B has .3 normalized shares, etc. Users who are sole members of an account have
the same number of normalized shares as the account. (E.g., User 1 has .3
normalized shares). Users who share accounts have a portion of the normalized
shares based on their shares. For example, if user 2 had been allocated 4
shares instead of 1, user 2 would have had .08 normalized shares. With users 2
and 3 each holding 1 share, they each have a normalized share of 0.05.
各アカウントに割り当てられたシェアにより、マシンの完全なリソースの正規化されたシェアを簡単に決定できます。アカウントAには.4の正規化シェアがあり、Bには.3の正規化シェアがあります。アカウントの唯一のメンバーであるユーザーは、アカウントと同じ数の正規化シェアを持っています。(たとえば、ユーザー1には0.3の正規化されたシェアがあります)。アカウントを共有するユーザーは、共有に基づいて正規化された共有の一部を持っています。たとえば、ユーザー2に1ではなく4のシェアが割り当てられていた場合、ユーザー2には0.08の正規化されたシェアがあったことになります。ユーザー2と3がそれぞれ1つのシェアを保持しているので、それぞれが0.05の正規化されたシェアを持っています。
Users 1, 2, and 4 have run jobs that have consumed the machine's computing resources. User 1's actual usage is 0.2 of the machine; user 2 is 0.25, and user 4 is 0.25.
ユーザー1、2、および4は、マシンのコンピューティングリソースを消費したジョブを実行しています。ユーザー1の実際の使用量はマシンの0.2です。ユーザー2は0.25、ユーザー4は0.25です。
The actual usage charged to each account is represented by the solid arrows. The actual usage charged to each account is summed as one goes up the tree. Account C's usage is the sum of the usage of Users 2 and 3; account A's actual usage is the sum of its children, accounts B and C.
各アカウントに請求される実際の使用量は、実線の矢印で表されています。各アカウントに請求される実際の使用量は、ツリーが上に行くにつれて合計されます。アカウントCの使用量は、ユーザー2と3の使用量の合計です。アカウントAの実際の使用量は、その子であるアカウントBとCの合計です。
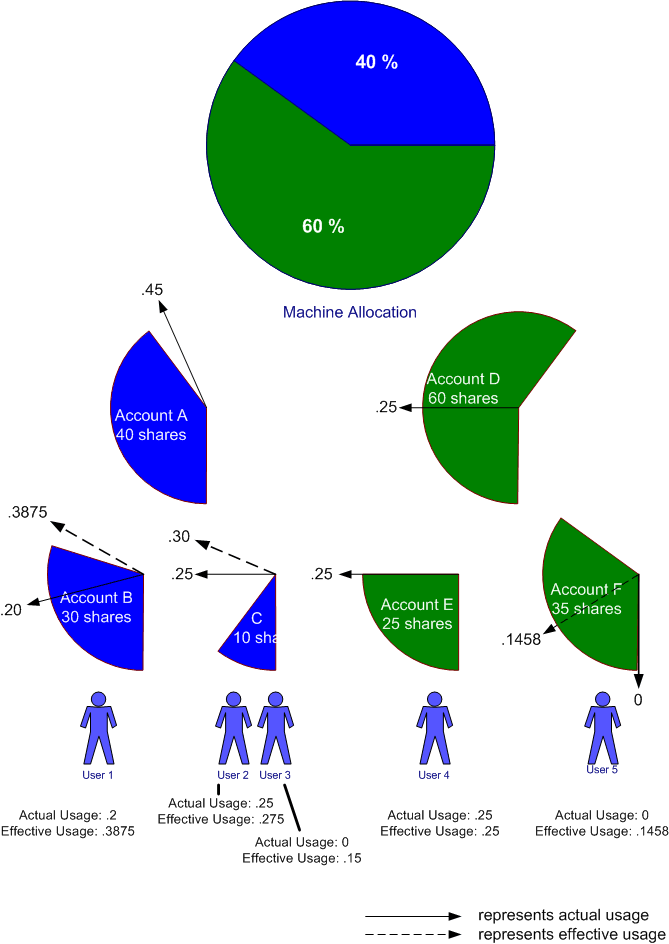
Figure 3. Fair-share Example
- User 1 normalized share: 0.3
- User 2 normalized share: 0.05
- User 3 normalized share: 0.05
- User 4 normalized share: 0.25
- User 5 normalized share: 0.35
As stated above, the effective usage is computed from the formula:
上記のように、有効使用量は次の式から計算されます。
UE = UAchild + ((UEparent - UAchild) * Schild/Sall_siblings)
The effective usage for all accounts at the first tier under the root allocation is always equal to the actual usage:
ルート割り当ての下の最初の層にあるすべてのアカウントの効果的な使用量は、常に実際の使用量と等しくなります。
したがって、アカウントAの有効使用量は.45になります。アカウントDの有効使用量は.25です。
- Account B effective usage: 0.2 + ((0.45 - 0.2) * 30 / 40) = 0.3875
- Account C effective usage: 0.25 + ((0.45 - 0.25) * 10 / 40) = 0.3
- Account E effective usage: 0.25 + ((0.25 - 0.25) * 25 / 60) = 0.25
- Account F effective usage: 0.0 + ((0.25 - 0.0) * 35 / 60) = 0.1458
The effective usage of each user is calculated using the same formula:
各ユーザーの有効使用量は、同じ式を使用して計算されます。
- User 1 effective usage: 0.2 + ((0.3875 - 0.2) * 1 / 1) = 0.3875
- User 2 effective usage: 0.25 + ((0.3 - 0.25) * 1 / 2) = 0.275
- User 3 effective usage: 0.0 + ((0.3 - 0.0) * 1 / 2) = 0.15
- User 4 effective usage: 0.25 + ((0.25 - 0.25) * 1 / 1) = 0.25
- User 5 effective usage: 0.0 + ((.1458 - 0.0) * 1 / 1) = 0.1458
Using the Slurm fair-share formula,
Slurmのフェアシェア式を使用して、
F = 2**(-UE/S)
the fair-share factor for each user is:
各ユーザーのフェアシェア係数は次のとおりです。
- User 1 fair-share factor: 2**(-.3875 / .3) = 0.408479
- User 2 fair-share factor: 2**(-.275 / .05) = 0.022097
- User 3 fair-share factor: 2**(-.15 / .05) = 0.125000
- User 4 fair-share factor: 2**(-.25 / .25) = 0.500000
- User 5 fair-share factor: 2**(-.1458 / .35) = 0.749154
From this example, once can see that users 1,2, and 3 are over-serviced while user 5 is under-serviced. Even though user 3 has yet to submit a job, his/her fair-share factor is negatively influenced by the jobs users 1 and 2 have run.
この例から、ユーザー5のサービスが不足しているときに、ユーザー1、2、および3のサービスが過剰であることがわかります。ユーザー3はまだジョブを送信していませんが、ユーザー1と2が実行したジョブによって、彼/彼女のフェアシェア係数はマイナスの影響を受けます。
Based on the fair-share factor alone, if all 5 users were to submit a job charging their respective accounts, user 5's job would be granted the highest scheduling priority.
フェアシェア係数のみに基づいて、5人のユーザー全員がそれぞれのアカウントに課金するジョブを送信すると、ユーザー5のジョブに最高のスケジューリング優先順位が付与されます。
Last modified 11 June 2019